GPT-5.5是什么
GPT-5.5 是 OpenAI 推出最新旗舰大模型,定位为迄今最智能、最直观的 AI 系统。模型在智能体编程、计算机使用、知识工作和科学研究四大领域实现显著跃升,Terminal-Bench 2.0 达 82.7%,SWE-Bench Pro 达 58.6%。GPT-5.5 与英伟达 GB200/GB300 NVL72 系统从训练到部署联合设计,在保持与 GPT-5.4 相当延迟的同时,用更少的 token 完成同等任务。模型现已向 ChatGPT Plus/Pro 及 Codex 用户开放。

GPT-5.5的主要功能
智能体编程:支持端到端代码实现、重构、调试与测试,可自主规划并执行复杂开发任务。
计算机使用:具备视觉感知与 GUI 操作能力,可自动点击、输入、跨工具导航完成工作流程。
知识工作:生成文档、表格、PPT,进行运营研究、数据建模,将杂乱业务输入转化为可执行计划。
科学研究:辅助多阶段科学数据分析、基因表达研究、数学证明探索,充当”合作科学家”。
工具调用:自主使用插件、浏览网页、分析数据,在多步骤任务中检查输出与自我纠错。
GPT-5.5的技术原理
智能体推理架构:采用端到端任务规划与执行框架,模型可自主拆解多部分任务、调用工具、验证输出并在模糊情境下持续迭代,无需人工逐步干预。
软硬件协同设计:与 NVIDIA GB200/GB300 NVL72 系统从训练到推理全栈联合设计,实现模型架构与硬件基础设施的双向优化。
动态推理优化:将推理视为集成系统而非孤立优化,通过动态负载均衡与分区启发式算法替代固定静态分块,使 GPU 利用率提升 20% 以上。
上下文感知机制:支持 400K(Codex)至 1M(API)超长上下文窗口,采用高效注意力机制在大规模代码库与文档中保持长期记忆与跨文件推理。
多模态感知与操作:融合视觉理解能力,可解析屏幕内容并执行精确的 GUI 操作,实现跨应用程序的自主计算机使用。
GPT-5.5 的性能体现
智能体终端操作:Terminal-Bench 2.0 达 82.7%,较 GPT-5.4 的 75.1% 和 Claude Opus 4.7 的 69.4% 显著领先,复杂命令行工作流完成率大幅提升。
真实代码修复:SWE-Bench Pro 达 58.6%,端到端解决 GitHub 问题的能力超越前代,单次通过即可完成更多任务。
知识工作评估:GDPval 达 84.9%,覆盖 44 种职业的知识工作任务表现优于 Claude Opus 4.7 的 80.3% 和 Gemini 3.1 Pro 的 67.3%。
计算机自主操作:OSWorld-Verified 达 78.7%,在真实计算机环境中自主完成复杂操作的能力行业领先。
客服工作流:Tau2-bench Telecom 达 98.0%,无需提示词调优即可处理复杂客户服务流程。
金融建模:FinanceAgent 达 60.0%,内部投资银行建模任务达 88.5%,专业财务分析能力突出。
数学推理:FrontierMath 达 51.7%,高难度数学问题(Tier 3 & 4)达 35.4%,远超 Claude Opus 4.7 的 22.9%。
网络安全:CyberGym 达 81.8%,在高级网络安全能力评估中表现优于竞品。
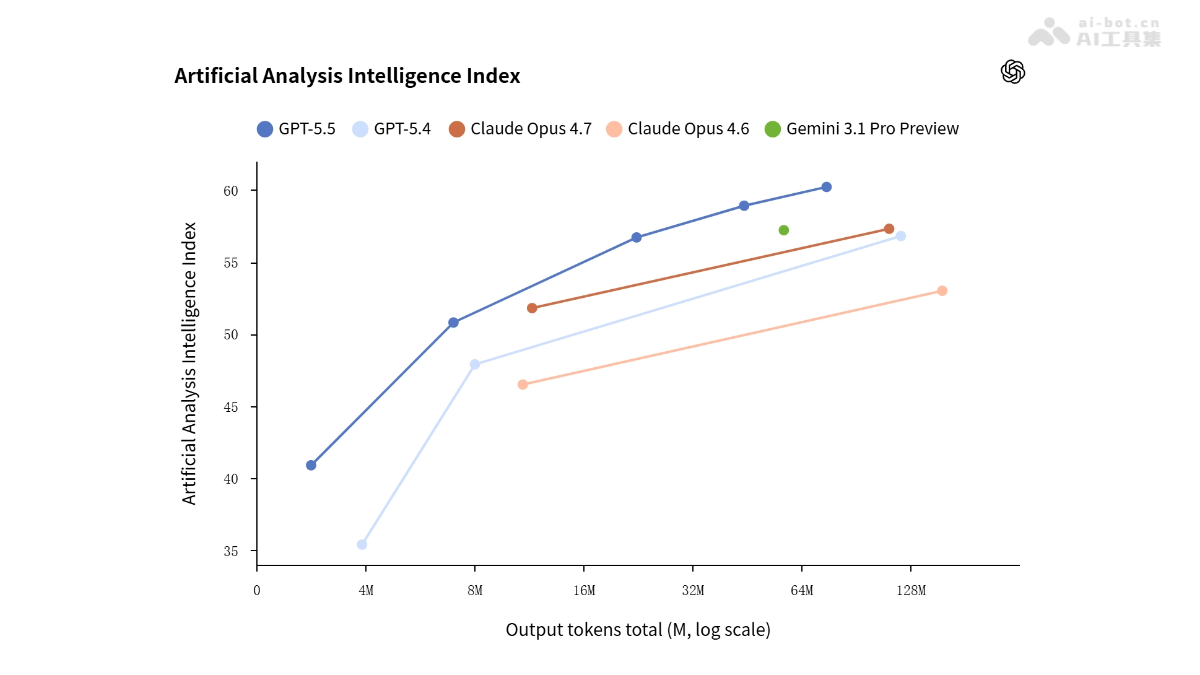
推理效率:在 Artificial Analysis Intelligence Index 上,相同 token 消耗下得分更高,或相同得分下所需 token 更少,实现智能与效率双优。
延迟控制:在真实生产环境中逐 token 延迟与 GPT-5.4 持平,打破”更强必更慢”的扩展定律。
如何使用 GPT-5.5
ChatGPT 用户:访问ChatGPT官网,Plus/Pro/Business/Enterprise 用户已可在模型选择器切换至 GPT-5.5 Thinking;Pro 用户额外可用 GPT-5.5 Pro。
Codex 用户:访问Codex官网,Plus/Pro/Business/Enterprise/Edu/Go 计划用户可在 Codex 中选择 GPT-5.5,支持 400K 上下文与 Fast 模式。
API 开发者:模型即将上线 Responses 与 Chat Completions API。
安全访问:从事网络防御的可信组织可申请 Trusted Access for Cyber,通过 chatgpt.com/cyber 减少防御性工作的使用限制。
GPT-5.5的关键信息和使用要求
发布状态:2026 年 4 月 24 日正式发布,已向订阅用户推送,API 即将开放。
订阅要求:ChatGPT 需 Plus 及以上;Codex 覆盖 Plus 至 Go 全档位;GPT-5.5 Pro 仅限 Pro/企业用户。
上下文窗口:Codex 支持 400K;API 标准版支持 1M token。
安全机制:部署迄今最强防护措施,包括网络安全分类器、生物/化学能力评估及外部红队测试。
硬件依赖:推理基于英伟达 GB200/GB300 NVL72 系统,Fast 模式需额外付费(2.5 倍成本,1.5 倍速度)。
GPT-5.5的核心优势
性能跃升:Terminal-Bench 2.0 达 82.7%,SWE-Bench Pro 达 58.6%,GDPval 达 84.9%,均领先前代与竞品。
效率突破:与 GPT-5.4 延迟相当,完成相同 Codex 任务消耗 token 显著更少,成本效率更优。
深度推理:具备”概念清晰度”,能理解系统架构、预判失败原因、预测测试需求,无需逐步拆解任务。
硬件协同:与英伟达 GB200/GB300 NVL72 联合设计,从训练到推理实现软硬件深度优化。
持久自主:在长周期复杂任务中保持专注,减少中途停止,支持 400K 上下文窗口。
GPT-5.5的项目地址
- 项目官网:https://openai.com/index/introducing-gpt-5-5/
GPT-5.5的同类竞品对比
| 对比维度 | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 69.4% | 68.5% |
| SWE-Bench Pro | 58.6% | — | — |
| GDPval | 84.9% | 80.3% | 67.3% |
| OSWorld-Verified | 78.7% | 78.0% | — |
| FrontierMath (Tier3&4) | 35.4% | 22.9% | 16.7% |
| 上下文窗口 | 1M (API) / 400K (Codex) | 200K | 1M |
| 编程自主性 | 高,支持端到端任务 | 中高 | 中 |
| 延迟表现 | 与 GPT-5.4 持平 | 较慢 | 中等 |
| API 输出定价 | $30/百万 token | $75/百万 token | — |
| 硬件协同 | 英伟达 GB200/GB300 联合设计 | 无 | 谷歌 TPU |
GPT-5.5的应用场景
软件开发:从自然语言需求直接生成可运行应用,处理大规模代码库重构与跨分支合并。
企业运营:自动分析六个月业务数据、构建评分框架、审核税务表单,加速财务与沟通流程。
科学研究:分析数万样本基因数据集、辅助组合数学证明、构建生物信息学可视化工具。
网络安全:为可信防御者提供高级安全能力,支持代码审计、漏洞修补与基础设施防护。
日常办公:通过 ChatGPT 处理复杂研究、信息综合、文档分析,提升知识工作者效率。