Composer 2.5是什么
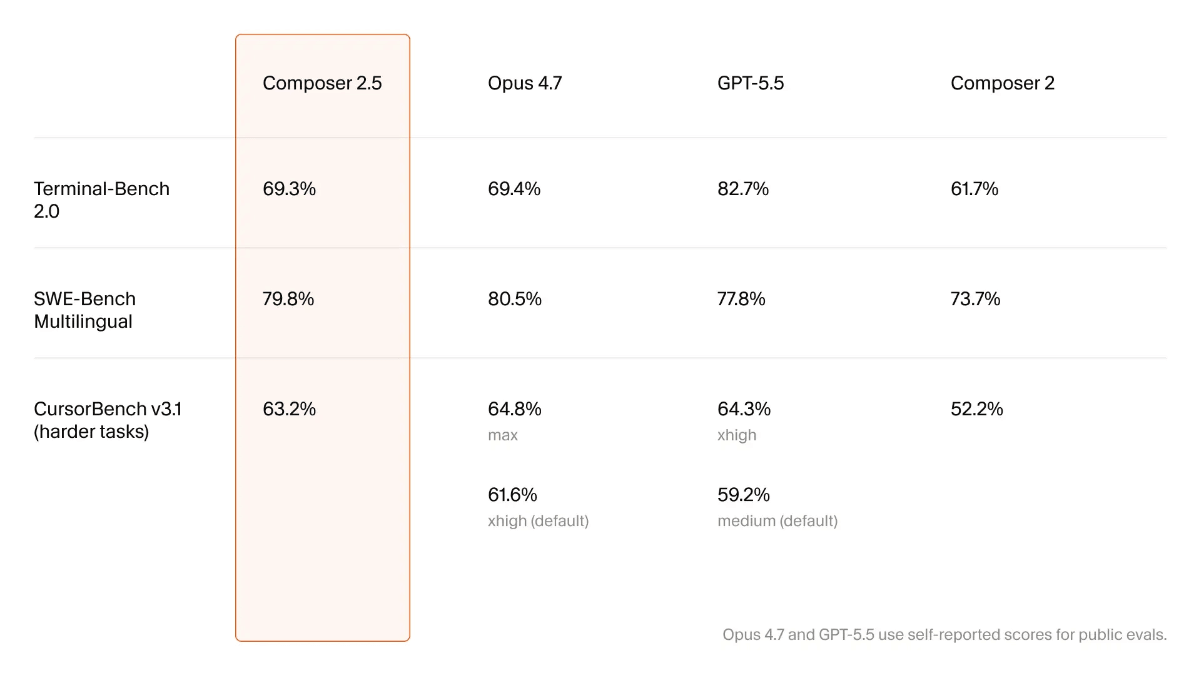
Composer 2.5 是 Cursor 推出的自研 Agentic 编程模型。在智能水平和行为表现上较 Composer 2 有大幅提升,在 SWE-Bench Multilingual(79.8%) 和 CursorBench v3.1(63.2%) 等核心基准上与 Claude Opus 4.7、GPT-5.5 处于同一梯队,但单次任务成本仅为竞品的约 1/10,称为”性价比之王”。模型基于 Moonshot 开源的 Kimi K2.5 检查点持续训练,目前仅通过 Cursor IDE 及 SDK 提供服务。
Composer 2.5的主要功能
长时任务持续工作:针对长时间运行的 Agent 会话深度优化,能在多步骤工具调用中保持专注,显著减少中途幻觉或提前终止的问题。
复杂指令可靠遵循:对跨文件重构、终端命令执行、测试驱动开发等复杂指令的遵循可靠性较 Composer 2 大幅提升。
努力级别动态校准:模型能根据任务难度自动分配计算量,简单任务快速完成,复杂任务深入思考,避免”小事空转、大事欠思考”。
沟通风格优化:回复更简洁结构化,减少不必要的冗长解释,在多文件变更时提供更清晰的推理过程。
工具调用精准度提升:显著减少无效的终端命令或冗余搜索,提升代码检索与终端操作效率。
双版本灵活适配:提供 Standard(标准版,$0.50/$2.50 per M tokens)与 Fast(快速版,$3.00/$15.00 per M tokens),智能水平相同,分别适配后台批量任务与交互式实时编程。
如何使用Composer 2.5
在 Cursor IDE 中启用:将 Cursor 更新至 2026 年 5 月最新稳定版,打开 Composer 面板(
Cmd+I/Ctrl+I),点击模型选择器切换至 Composer 2.5选择速度档位:交互式开发默认使用 Fast 版(响应快、延迟低);后台 Agent 或批量任务可在 Settings > Models 中切换为 Standard 版(成本低,智能水平相同)
通过 SDK 程序化调用:
import { Agent } from "@cursor/sdk";const agent = await Agent.create({model: "composer-2.5",// Standard 版// model: "composer-2.5-fast", // Fast 版workspace: "./",tools: ["edit", "shell", "search", "browser"],});为长时任务设限:为无人看管的长时间 Agent 会话设置迭代次数上限和最大耗时,防止模型利用缓存等”捷径”进行奖励作弊
领取首发福利:发布首周提供双倍用量额度,可在后台查看额度消耗情况
多模型路由策略:将 90% 日常任务交给 Composer 2.5 处理;仅将架构评审类任务路由给 Claude Opus 4.7,重度终端 Shell 任务路由给 GPT-5.5
Composer 2.5的核心优势
极致性价比:Standard 版输入 $0.50/M、输出 $2.50/M,Fast 版输入 $3.00/M、输出 $15.00/M,比 Claude Opus 4.7 便宜约 10~30 倍。
前沿级基准表现:SWE-Bench Multilingual 79.8%(Opus 4.7 为 80.5%,GPT-5.5 为 77.8%),CursorBench v3.1 63.2%(与 Opus 4.7 的 64.8% 和 GPT-5.5 的 64.3% 基本持平)。
行为层面深度优化:除了扩大训练规模,还改进了沟通风格和投入级别校准,这些维度虽难被基准充分反映,但对实际使用体验至关重要。
双版本灵活选择:Standard(标准版)适合后台 Agent 与批量任务,Fast(快速版,默认)适合交互式 IDE 实时编程,两者智能水平完全相同。
首发双倍用量福利:发布首周提供双倍用量额度。
Composer 2.5的同类竞品对比
| 对比维度 | Composer 2.5 | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|---|
| 厂商 / 平台 | Cursor | Anthropic | OpenAI |
| 产品定位 | 自研 Agentic 编程模型 | 旗舰推理模型 | 旗舰多模态模型 |
| 基座模型 | Moonshot Kimi K2.5(开源检查点持续训练) | Claude 4 系列 | GPT-5 系列 |
| 发布日期 | 2026.05.18 | 2026 年 Q2 | 2026 年 Q2 |
| SWE-Bench Multilingual | 79.8% | 80.5% | 77.8% |
| Terminal-Bench 2.0 | 69.3% | 69.4% | 82.7% |
| CursorBench v3.1(困难任务) | 63.2% | 64.8%(max)/ 61.6%(默认 xhigh) | 64.3%(xhigh)/ 59.2%(默认 medium) |
| 输入价格(/M tokens) | $0.50(Standard)< $3.00(Fast) | 未公开(行业参考约 $15) | 未公开(行业参考约 $3–$5) |
| 输出价格(/M tokens) | $2.50(Standard)< $15.00(Fast) | 未公开(行业参考约 $75) | 未公开(行业参考约 $15–$30) |
| 单次任务相对成本 | 基准(约 $1–$2 / 任务) | 约 10–30 倍 | 约 3–10 倍 |
| 上下文窗口 | ~200K(参考 Kimi K2.5) | 200K | 128K–1M |
| 权重开放性 | 闭源(仅 Cursor 基础设施) | 闭源 | 闭源 |
| 接入方式 | Cursor IDE / CLI / @cursor/sdk | API / Claude Code / 第三方平台 | API / ChatGPT / GitHub Copilot |
Composer 2.5的应用场景
多文件级重构:成本优势明显且精度持平前沿模型,适合大规模代码库迁移。
交互式结对编程:Fast 版响应迅速,适合实时 IDE 协作。
后台定时任务/云 Agent:Standard 版性价比极高,适合批量代码审查与修复。
测试驱动开发:长时任务可靠性优于前代,能稳定完成多轮测试-修复循环。
复杂终端自动化:Terminal-Bench 2.0 得分 69.3%,与 Opus 4.7(69.4%)持平,但重度 Shell 场景仍略逊于 GPT-5.5(82.7%)。