Polar是什么
Polar 是英伟达推出的开源智能体强化学习(Agentic RL)训练框架,核心创新在于无需修改现有智能体框架内部代码,可将其接入 GRPO 等 RL 算法进行训练。框架通过在 LLM API 调用边界放置代理,捕获 token 级交互数据并重建训练轨迹,使 Codex CLI、Claude Code、Qwen Code、Pi 等复杂代码智能体 harness 直接变为可训练的 RL 环境。
Polar的主要功能
API 代理捕获:在智能体与推理服务器之间插入兼容 Anthropic、OpenAI、Google 风格的 API 代理,透明转发请求并记录 prompts、sampled tokens、log probabilities 和 responses。
轨迹重建:提供 per-request(逐请求)和 prefix merging(前缀合并)两种策略,将多轮模型调用重建为训练器可直接消费的 RL 轨迹。
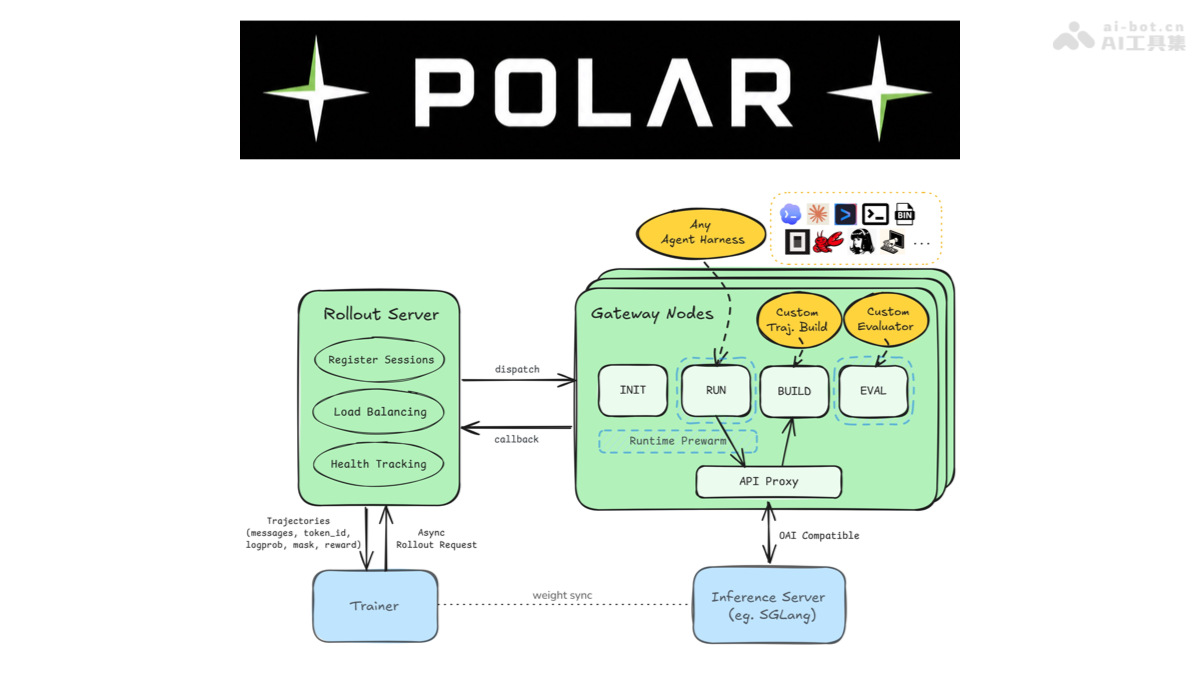
异步服务架构:Rollout Server 负责任务调度与负载均衡,Gateway Nodes 负责运行时预热、智能体执行、轨迹构建和评估,解耦训练与执行。
多 Harness 兼容:内置 Claude Code、Codex、Qwen Code、OpenCode、Pi、Gemini CLI 等主流代码智能体的快捷适配。
容器化运行时:支持 Docker 和 rootless Apptainer,提供隔离执行环境。
Polar的技术原理
黑盒代理范式:Polar 不将智能体 harness 改写为 env.init()/env.step() 接口,而是将 LLM API 流量作为 rollout 边界,保持 harness 原生执行逻辑不变。
Token 保真轨迹重建:直接从推理后端获取 token IDs 和 log probabilities,避免 retokenization drift(重编码漂移),确保训练信号与行为策略严格对齐。
Prefix Merging 算法:检测多轮对话中 prompt 的 token-prefix 关系,将 append-only 的对话链合并为更长的训练轨迹,减少 trainer 更新次数。
异步分阶段执行:Gateway 内部分离 INIT(运行时启动)、RUN(harness 执行)、POSTRUN(轨迹构建与评估)三个独立工作池,配合 READY 缓冲区实现运行时预热与 GPU 训练并行。
权重同步机制:Trainer 与 Inference Server 之间异步同步模型权重,rollout 在旧策略上持续采样,trainer 在收到足够轨迹后执行策略更新。
如何使用Polar
部署 Polar 服务:启动 Rollout Server 和 Gateway Nodes,配置 Inference Server(如 SGLang)。
配置 Harness:将目标智能体(如 Codex CLI)的模型 base URL 指向 Polar Gateway 代理端点。
编写适配器:创建 harness adapter(通常只需配置环境变量、provider 设置和启动命令)。
提交训练任务:通过 Polar API 提交 TaskRequest,指定 harness、运行时、评估器和轨迹构建策略。
接入 Trainer:训练框架(如 Slime、Megatron)通过回调接收 Polar 返回的轨迹数据,执行 GRPO 等 RL 算法更新。
Polar的核心优势
零侵入集成:无需修改现有智能体框架源码,降低接入 RL 训练的技术门槛。
Harness 无关性:兼容任意基于 LLM API 的智能体,包括闭源二进制程序。
高效资源利用:异步架构使 CPU 密集型运行时准备不阻塞 GPU 训练,prefix merging 将训练时间缩短约 5.39 倍。
Token 级保真:直接从推理后端捕获原始 token,避免文本重编码带来的训练信号失真。
弹性扩展:Rollout-as-a-service 设计支持大规模分布式异步 RL 训练。
Polar的项目地址
- GitHub仓库:https://github.com/NVIDIA-NeMo/ProRL-Agent-Server
- arXiv技术论文:https://arxiv.org/pdf/2605.24220
Polar的同类竞品对比
| 维度 | Polar(英伟达) | SkyRL-Agent | Agent Lightning |
|---|---|---|---|
| 核心定位 | Rollout-as-a-Service 基础设施 | 全栈多轮 Agent RL 训练与评估系统 | 训练-智能体解耦架构 + 统一数据接口 |
| 集成侵入性 | 零侵入:API 代理拦截,无需改 harness 源码 | 需重写:需将 agent 适配到 Gymnasium 风格接口 | 低侵入:需接入标准追踪接口或 SDK 回调 |
| Harness 兼容性 | 任意黑盒 harness(含闭源二进制) | 仅限框架内实现的 agent | 需符合预设接口的 agent |
| Rollout 边界 | LLM API 流量边界 | Agent 执行逻辑内部 | Agent 执行追踪层 |
| 异步架构 | 原生异步服务边界(Server + Gateway Nodes) | 支持异步,但 agent 与训练紧耦合 | 有限异步支持 |
| 轨迹重建 | Token 保真 + Prefix Merging(减少 trainer 更新) | 框架内直接生成轨迹 | 统一数据接口转换 |
| 运行时隔离 | Docker / Apptainer | 支持容器化 | 未明确 |
| 训练算法耦合 | 与算法无关(GRPO / PPO 等均可接入) | 内置算法优化 | 与算法无关 |
| 代表场景 | Codex、Claude Code、Qwen Code 等现成 harness 的 RL 训练 | 长流程多轮工具使用 agent 训练 | 跨框架 agent 训练数据收集 |
Polar的应用场景
代码智能体强化学习:对 Codex、Claude Code 等编程助手进行 RL 微调,提升 SWE-Bench 等软件工程 benchmark 表现。
多轮工具使用 Agent 训练:训练需要持续调用外部工具(浏览器、数据库、API)的长流程智能体。
离线 SFT 数据生成:利用 Polar 在自定义 harness 上批量生成高质量训练数据,用于监督微调。
多智能体协作优化:对包含子智能体编排和上下文压缩的复杂多 Agent 系统进行端到端 RL 训练。
闭源 Agent 评估与改进:对无法获取源码的闭源智能体产品进行黑盒 RL 训练和能力提升。